Crowd-Sourced Plant Occurrence Data Provide a Reliable Description of Macroecological Gradients
Abstract
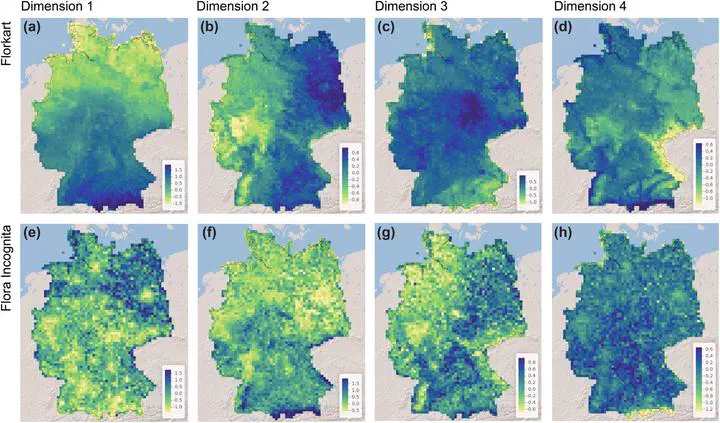
Deep learning algorithms classify plant species with high accuracy, and smartphone applications leverage this technology to enable users to identify plant species in the field. The question we address here is whether such crowd-sourced data contain substantial macroecological information. In particular, we aim to understand if we can detect known environmental gradients shaping plant co-occurrences. In this study we analysed 1 million data points collected through the use of the mobile app Flora Incognita between 2018 and 2019 in Germany and compared them with Florkart, containing plant occurrence data collected by more than 5000 floristic experts over a 70-year period. The direct comparison of the two data sets reveals that the crowd-sourced data particularly undersample areas of low population density. However, using nonlinear dimensionality reduction we were able to uncover macroecological patterns in both data sets that correspond well to each other. Mean annual temperature, temperature seasonality and wind dynamics as well as soil water content and soil texture represent the most important gradients shaping species composition in both data collections. Our analysis describes one way of how automated species identification could soon enable near real-time monitoring of macroecological patterns and their changes, but also discusses biases that must be carefully considered before crowd-sourced biodiversity data can effectively guide conservation measures.